This post explains how to install PostgreSQL on WSL2 for Windows, apply the necessary changes to PostgreSQL settings, and access the database from the Windows host. Even though this knowledge can be found in different bits and pieces spread out all over the internet, I want to compile a short and straightforward how-to article. I want you to be able to complete all the steps from scratch, without having to skip all over the place.
Why do I need PostgreSQL on WSL2?
Even though there is a strong feeling that a true programmer uses Linux in their work, this statement is not really close to the truth. At least, according to this Stack Overflow survey 2021:
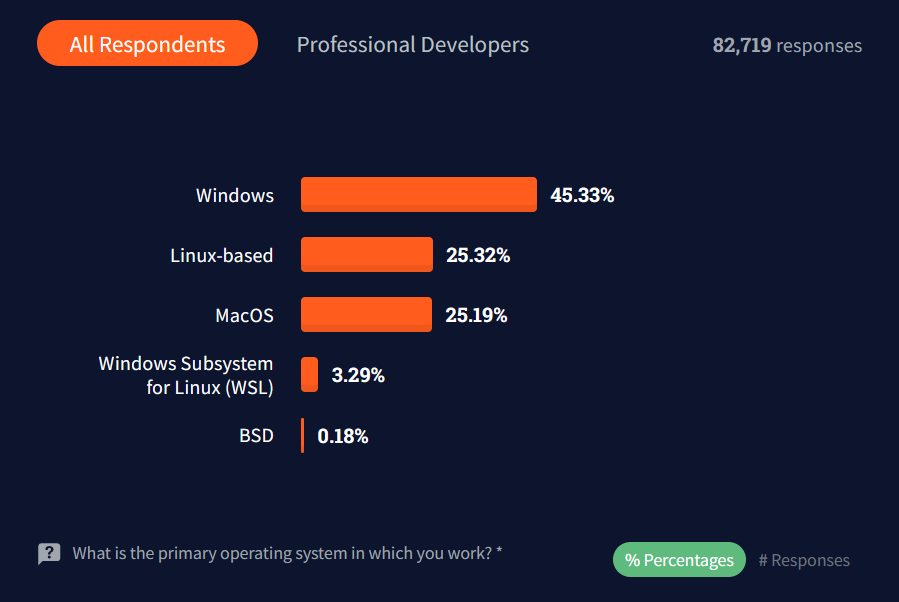
There are a ton of reasons why a developer might want to use WSL2 with PostgreSQL onboard, but let's name a few:
psql is the standard tool for learning and working with PostgreSQL. However, there are some limiting issues under Windows, e.g., the lack of tab completion, issues with encoding, etc. Running psql under WSL2 will provide you with a smoother experience.- It's a good idea to test and debug your application in a remote environment rather than on a local host. That way, you can immediately find issues with client authentication, or with connection settings. Since WSL2 is a standalone virtual machine under the hood, using it might be the easiest way to achieve this.
- WSL2 will provide the environment for advanced developers to build and test different PostgreSQL extensions not available in binary form or created exclusively for Linux, e.g., pg_squeeze, pg_show_plans, pg_crash, pg_partman, etc.
Install WSL2
To install WSL2 from PowerShell or the Windows Command Prompt, just run:
PS> wsl --install
From the manual:
- This command will enable the required optional components, download the latest Linux kernel, set WSL2 as your default, and install a Ubuntu distribution for you by default.
- The first time you launch a newly installed Linux distribution, a console window will open and you'll be asked to wait for files to de-compress and be stored on your machine. All future launches should take less than a second.
Supposing you prefer to change the distribution installed, you have the option to choose among those available. To list the known distros, run:
PS> wsl --list --online The following is a list of valid distributions that can be installed. Install using 'wsl --install -d <Distro>'. NAME FRIENDLY NAME Ubuntu Ubuntu Debian Debian GNU/Linux kali-linux Kali Linux Rolling openSUSE-42 openSUSE Leap 42 SLES-12 SUSE Linux Enterprise Server v12 Ubuntu-16.04 Ubuntu 16.04 LTS Ubuntu-18.04 Ubuntu 18.04 LTS Ubuntu-20.04 Ubuntu 20.04 LTS
After that, you can install the chosen Linux distribution on WSL2 by running the command:
PS> wsl --install -d Debian
Here in this post, I will use the Ubuntu distribution for demonstration purposes.
 All further commands are supposed to be executed in the Ubuntu WSL2 session.
All further commands are supposed to be executed in the Ubuntu WSL2 session.
I strongly suggest using Windows Terminal to work with console sessions.
Install PostgreSQL on WSL2 Ubuntu
Please follow the instructions on the official site:
$ sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list' $ wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add - $ sudo apt-get update $ sudo apt-get -y install postgresql postgresql-contrib $ psql --version psql (PostgreSQL) 14.0 (Ubuntu 14.0-1.pgdg20.04+1) $ sudo service postgresql status 14/main (port 5432): down $ sudo service postgresql start * Starting PostgreSQL 14 database server
Please take note: we are not using systemctl because WSL2 doesn't use systemd to operate:
$ sudo systemctl status postgresql System has not been booted with systemd as init system (PID 1). Can't operate. Failed to connect to bus: Host is down
Set up PostgreSQL on WSL2
Now we need to set up PostgreSQL so it will:
- accept connections from the Windows host;
- have custom-created users;
- allow authentication from remote hosts.
By the way, let me recommend my friend Lætitia Avrot's blog to you, where all these topics are covered.
How do I accept connections from the Windows host for PostgreSQL on WSL2?
 I'm aware that the newest WSL2 version allows localhost forwarding, but I think this topic is essential to know, especially in constructing a development environment!
I'm aware that the newest WSL2 version allows localhost forwarding, but I think this topic is essential to know, especially in constructing a development environment!
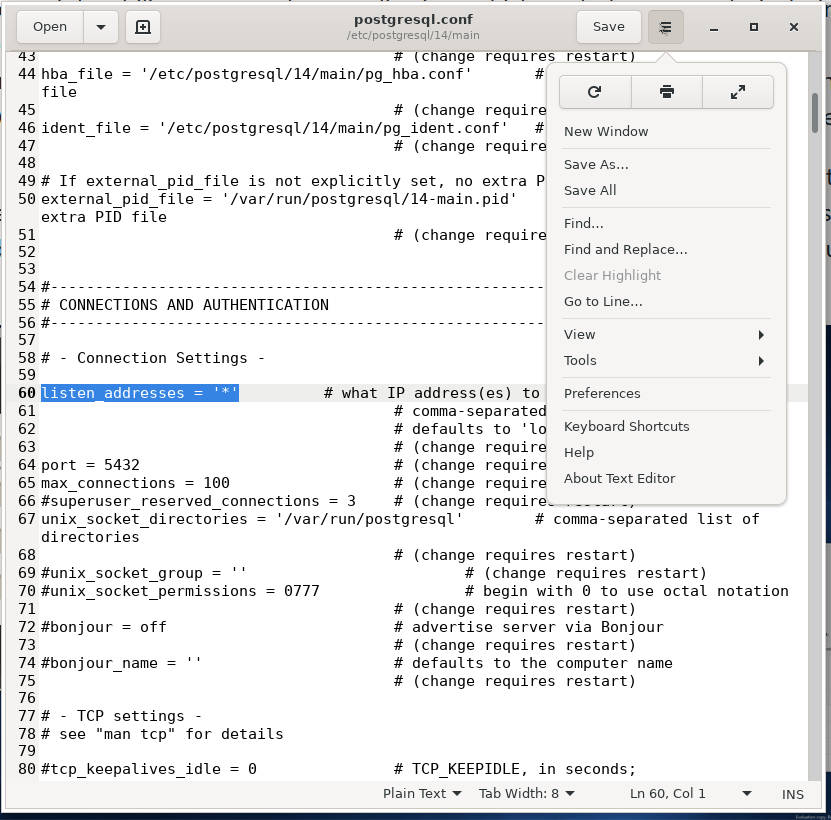
By default, every PostgreSQL installation listens on 127.0.0.1 only. That means you cannot access the database instance from a remote host, including the Windows host. This is not a bug. This is a security feature.
To change this setting, we need to:
- edit
postgresql.conf; - uncomment (sic!)
listen_address line; - change it to
listen_address = '*' for every available IP address or comma-separated list of addresses; - restart the PostgreSQL instance, so the new settings take effect.
Depending on your distro, the location of the postgresql.conf file may differ. The easiest way to know where it is is to ask the server itself. However, there is one catch here.
Right now, there is only one user available in our fresh PostgreSQL installation: postgres. And there is only one way to connect to the instance: peer authentication.
That means the operating system (Ubuntu on WSL2) should provide a user name from the kernel and use it as the allowed database user name:
sudo -u postgres psql -c 'SHOW config_file' config_file ----------------------------------------- /etc/postgresql/14/main/postgresql.conf (1 row)
If you are struggling to understand what this command does, I suggest you visit the fantastic explainshell.com site!
Now let's do something fun! The latest WSL2 is so cool that it allows you to run GUI Linux applications! So instead of using a TUI editor like nano or vim, we will use Gedit!
$ sudo apt install gedit -y $ sudo gedit /etc/postgresql/14/main/postgresql.conf $ sudo service postgresql restart
How do I add users to a PostgreSQL cluster?
As I said, by default, there is only one user available: postgres . I strongly recommend creating a separate user.
Here we will use the same trick to connect to PostgreSQL with psql, and execute the CREATE USER command:
$ sudo -u postgres psql psql (14.0 (Ubuntu 14.0-1.pgdg20.04+1)) Type "help" for help. postgres=# CREATE USER dev PASSWORD 'strongone' CREATEDB; CREATE ROLE postgres=# \q
Now we can specify our newly created user dev and connect to PostgreSQL using password authentication. Please note that I explicitly used the -h 127.0.0.1 parameter to force password authentication instead of peer authentication.
$ psql -U dev -h 127.0.0.1 -d postgres Password for user dev: psql (14.0 (Ubuntu 14.0-1.pgdg20.04+1)) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off) Type "help" for help. postgres=>\q
How can I allow authentication from remote hosts for PostgreSQL on WSL2?
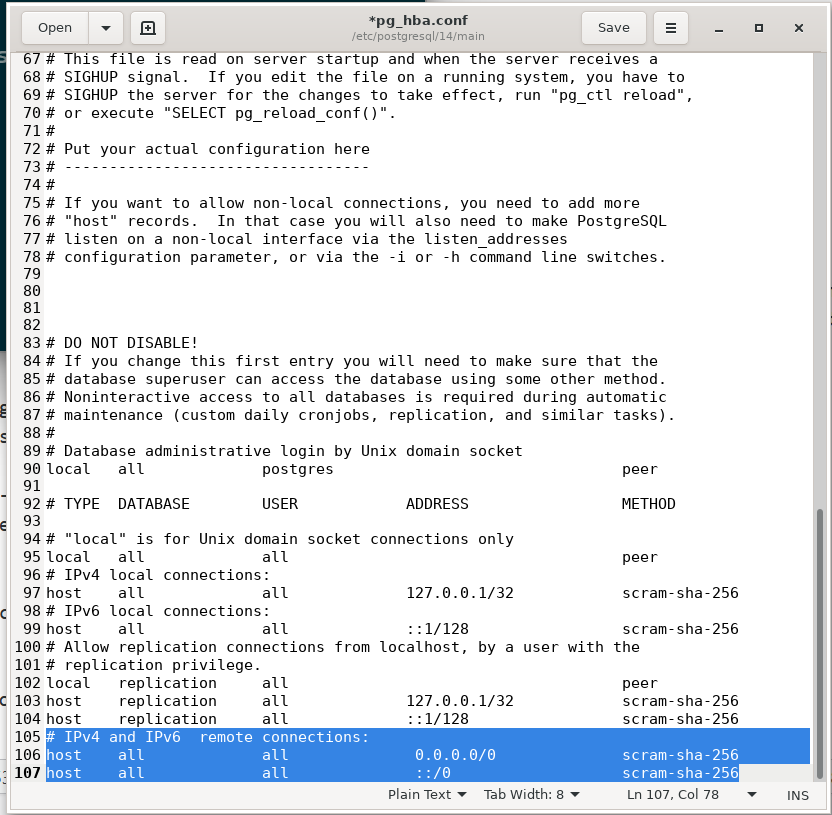
The easiest way would be to add additional lines to the pg_hba.conf file:
.. host all all 0.0.0.0/0 scram-sha-256 host all all ::/0 scram-sha-256
This change will apply scram-sha-256 password authentication for all IPv4 and IPv6 connections.
$ sudo -u postgres psql -c 'SHOW hba_file' hba_file ------------------------------------- /etc/postgresql/14/main/pg_hba.conf (1 row) $ sudo gedit /etc/postgresql/14/main/pg_hba.conf $ sudo service postgresql restart
How do I connect to PostgreSQL on WSL2 from a Windows host?
With the latest WSL2 version, you can access PostgreSQL from a Windows app (like psql or pgAdmin) using localhost (just like you usually would):
PS> psql -U dev -d postgres Password for user dev: psql (13.0, server 14.0 (Ubuntu 14.0-1.pgdg20.04+1)) WARNING: psql major version 13, server major version 14. Some psql features might not work. WARNING: Console code page (65001) differs from Windows code page (1251) 8-bit characters might not work correctly. See psql reference page "Notes for Windows users" for details. SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off) Type "help" for help. postgres=>\q
But if you have conflicts with, for example, a local (Windows) PostgreSQL installation, you might want to use the specific WSL2 IP address. The same applies if you are running an older version of Windows (Build 18945 or less).
As I mentioned earlier, the WSL2 system is a standalone virtual machine with its own IP address. So first, we need to know the IP address to connect. There are several ways to do so. Choose whatever you prefer.
You can run such a command in the WSL2 session:
$ ip addr show eth0 6: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000 link/ether 00:15:5d:19:85:ca brd ff:ff:ff:ff:ff:ff inet 192.168.176.181/20 brd 192.168.191.255 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::215:5dff:fe19:85ca/64 scope link valid_lft forever preferred_lft forever
Or even shorter– if you don't need all those details:
$ hostname -I 192.168.176.181
Or, you can run one of these commands from PowerShell, or from the Command Prompt session in the Windows host:
PS> bash -c "hostname -I" 192.168.176.181 PS> wsl -- hostname -I 192.168.176.181
Now that we know the IP address, we can connect to PostgreSQL on WSL2 with psql:
PS> psql -U dev -d postgres -h 192.168.176.181 Password for user dev: psql (13.0, server 14.0 (Ubuntu 14.0-1.pgdg20.04+1)) WARNING: psql major version 13, server major version 14. Some psql features might not work. WARNING: Console code page (65001) differs from Windows code page (1251) 8-bit characters might not work correctly. See psql reference page "Notes for Windows users" for details. SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off) Type "help" for help. postgres=> \q
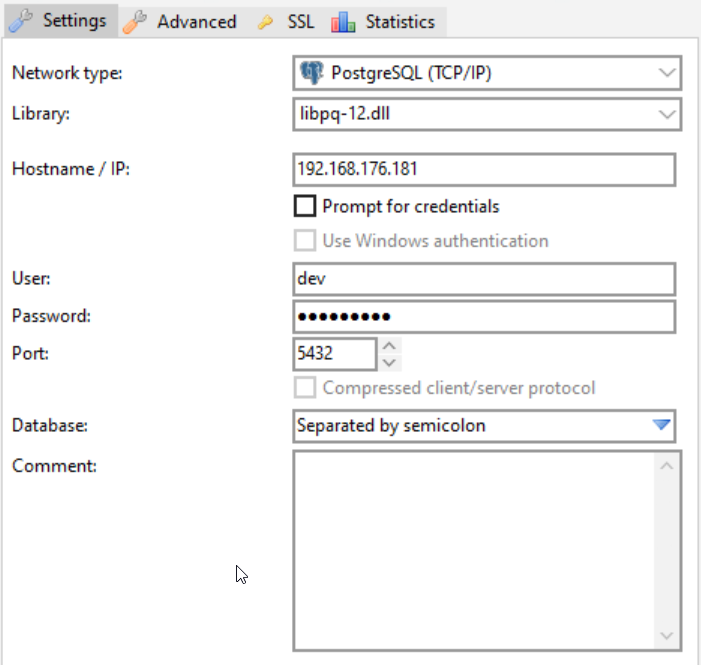
Or connect with any GUI you prefer, for example, with HeidiSQL:
The only drawback is that the WSL2 machine IP address cannot be made static! That means you will need to check the IP address after each restart or set up some startup script to update the system environment variable of some file content with the current IP. Since there is no universal solution, I will leave that as homework for the reader. 
Conclusion
In this post, we learned:
- how to install WSL2;
- the way to install PostgreSQL on the default WSL2 distro Ubuntu;
- how to set up PostgreSQL to listen on all IP addresses;
- how to set up PostgreSQL to authenticate users from all IP addresses;
- some tricks, software, and services.
Let me know if this topic is interesting for you and the issues we should highlight in the follow-up articles.
Here's where you can find more Windows-specific posts you may find helpful.
In conclusion, I wish you all the best! 
Please, stay safe – so we can meet in person at one of the conferences, meetups, or training sessions!
The post PostgreSQL on WSL2 for Windows: Install and setup appeared first on CYBERTEC.

 A new version of
A new version of 

